Laravel-native evaluation framework for RAG / LLM applications. Golden datasets in YAML, seven built-in metrics, standalone output assertions, Markdown + JSON reports, and an Artisan CI gate. Stop shipping silent regressions in your AI pipeline.

![]()




- Why eval-harness?
- Design rationale
- Features
- Comparison with alternatives
- Installation
- Quick start
- Usage examples
- Web admin panel UI
- Contract stability and migration
- Configuration
- Architecture
- AI vibe-coding pack included
- Testing
- Roadmap
- Contributing
- Security
- License
Imagine deploying a RAG-powered chatbot to production. Quality is great on launch day. Three months later, somebody:
- bumps the embedding model from
text-embedding-3-smalltotext-embedding-3-large, - swaps the chat model from
gpt-4otogpt-4o-minifor cost, - tweaks the prompt template,
- updates
laravel/aifrom^0.5to^0.6, - changes the chunker from 800-token sliding window to 1200-token semantic.
Every one of those changes is a quality regression risk, and you have no programmatic signal they shipped intact. Your test suite green-lights the deployment because PHPUnit doesn't know what a "correct answer" looks like.
padosoft/eval-harness fixes that loop:
- You curate a small golden dataset — a YAML file with 30-200
(question, expected answer)pairs that represent the queries you actually care about. - You declare metrics — exact-match for deterministic outputs, cosine-embedding for paraphrase tolerance, LLM-as-judge for subjective grading.
- You wire up a callable that drives your real pipeline against the dataset.
- CI runs
php artisan eval-harness:run rag.factualityon every PR and gates the merge on the macro-F1 score.
Now your AI pipeline has the same regression protection your business logic has had for the last fifteen years.
The package is opinionated. Three decisions matter most:
1. No SDK lock-in. Every external call goes through Laravel's
Http:: facade — never an OpenAI / Anthropic / Vertex SDK. Tests
substitute via Http::fake() for deterministic offline runs, and
swapping providers is a config-file change, not a refactor.
2. The dataset is YAML, not a Laravel model. YAML is reviewable
in pull requests, diffable across releases, and survives database
wipes. The package never stores datasets in your DB — they live in
eval/golden/*.yml next to your code.
3. Failures are captured by default. A timeout on sample 47
should not mask the macro-F1 score across 200 valid samples. Every
metric exception is recorded against (sample, metric) and
surfaced in the final report so the operator can investigate, not
re-run the whole 30-minute suite. Strict CI lanes can opt into
EVAL_HARNESS_RAISE_EXCEPTIONS=true to abort on the first
MetricException provider/metric contract error.
These decisions cost some flexibility (you can't dispatch metrics across multiple processes yet — see Roadmap) but they keep the public surface small and the offline path fast.
- Nine metrics out of the box —
exact-match,contains,regex,rouge-l,citation-groundedness,cosine-embedding,bertscore-like,llm-as-judge,refusal-quality— and a cleanMetricinterface for adding more. - Strict-schema YAML loader — versioned dataset contracts and actionable validation errors for malformed samples.
- Deterministic LLM-as-judge — temperature 0, seed 42,
response_format=json_object. Strict-JSON parser rejects malformed responses instead of silently scoring 0. - Stable JSON report shape — every payload carries explicit
schema_versionanddataset_schema_versionfields. Wire into your CI dashboard once, then evolve additively. - Cohort-ready report data — JSON and Markdown reports aggregate
scores by
metadata.tags, expose an explicit untagged bucket, and include per-metric score histograms for dashboards. - Citation evidence checks —
citation-groundednesscan score simple citation markers or strictermetadata.citation_evidencespans that require both citation markers and quote text. - Opt-in adversarial lane —
AdversarialDatasetFactoryandphp artisan eval-harness:adversarialbuild/run safety regression seeds for prompt injection, jailbreaks, data leaks, SSRF, tool abuse, and similar red-team categories. JSON/Markdown reports add category and compliance-framework summaries, and optional manifests retain adversarial run summaries while preserving latest failure-free baselines per compatible report schema, dataset, metric names, and adversarial category/sample-count slice under tight retention;--regression-gatefails CI when macro-F1 or configured metric aggregates drop, and--promote-failureswrites failed samples back to a reloadable YAML dataset seed. Scheduler/CI guidance shows how to run the lane continuously without bundling a daemon in this package. - Standalone output assertions — score saved JSON/YAML outputs with the same metrics and report contract, without invoking your agent in CI.
- Usage summaries — JSON and Markdown reports aggregate structured
usagedetails for provider token counts, cost USD, and latency. - Runtime guardrails — provider timeouts are normalized, optional
retries cover Laravel HTTP connection failures plus HTTP 429/5xx,
and strict mode can rethrow
MetricExceptionfailures instead of capturing them. - Batch execution modes — SUT runs flow through deterministic
SerialBatchby default, or queue-backedLazyParallelBatchvia--batch=lazy-parallelfor Laravel queue/Horizon workers. - Operational batch profiles —
--batch-profile=ci|smoke|nightlyapplies named presets of batch defaults (concurrency, queue, timeouts, chunk size, rate limit, checkpoint cadence, result TTL). Explicit CLI flags always win; host apps can override or add profiles undereval-harness.batches.profiles.*inconfig/eval-harness.php. - Producer-side backpressure —
--chunk-size=N,--rate-limit=N --rate-window-seconds=W, and--result-ttl-secondsbound dispatch in flight, throttle to N samples per W-second sliding window (monotonic-clock math, amortized O(1)), and size result metadata TTL for delayed collection. Passnoneon any nullable numeric flag to clear an inherited profile value for a one-off run. - Progress checkpoints and terminal status —
--checkpoint-every=Nemits structured progress events through an optionalBatchProgressReportercontainer binding (defaultNullBatchProgressReporter). Dashboards that need to distinguish a finished failed batch from a stalled one can implement the optionalBatchTerminalProgressReportersub-contract for explicitsuccess/failure/emptyterminal status with partial-wins tolerance on the failure path. - Live batch registry endpoints —
GET /<configured-prefix>/batches/liveandGET /<configured-prefix>/batches/{id}/progressexpose active lazy-parallel batch ids and compact progress counters through cache-backed read-only API contracts. The live registry is enabled by default and can be disabled witheval-harness.batches.live_registry.enabled. - Adversarial manifest discovery endpoints —
GET /<configured-prefix>/adversarial/manifestsandGET /<configured-prefix>/adversarial/manifests/{name}enumerate adversarial run manifests written to a configured disk so a companion UI can browse compliance history without scraping the filesystem. Opt-in viaeval-harness.adversarial.manifests.{disk,path_prefix}; the CLI--adversarial-manifest=<arbitrary-path>flag is preserved for existing operators. - Report diff endpoint —
GET /<configured-prefix>/reports/{id}/diff/{otherId}computes signed deltas (macro_f1, per-metric mean/pass_rate, per-cohort status withadded/removed/regressed/improved/stable, total_samples / total_failures, adversarial categories when present) so a companion UI can show regression diffs side-by-side without fetching full reports. The prefix defaults toeval-harness/apiand is configurable througheval-harness.api.prefix. - Dataset trend endpoint —
GET /<configured-prefix>/datasets/{name}/trend?limit=Nscans stored JSON reports for one dataset, skips malformed artifacts, capslimitat 100, caps scanned JSON files througheval-harness.api.trend.max_files_scanned, and returns chronological points with metrics, cohorts, usage, and theeval-harness.report-api.v1.trendschema discriminator. - Provider-agnostic — works with OpenAI, OpenRouter, Regolo, Mistral, any OpenAI-compatible chat-completions endpoint.
- No DB migrations required — datasets are YAML, results are JSON. The package adds zero rows to your schema.
- Artisan-driven CI gate —
php artisan eval-harness:runexits non-zero on any captured failure. Wire it into the same workflow your unit tests run in. - Architecture tests included — every release proves it doesn't leak symbols from sibling packages, ever.
Status legend: ✅ YES means first-class support, ⚠️ partial means supported with limits or outside the Laravel-native path, and ❌ NO means not a primary fit.
| Concern | eval-harness | OpenAI Evals | LangSmith | Ragas | Promptfoo | DeepEval |
|---|---|---|---|---|---|---|
| Laravel-native package | ✅ YES - PHP/Laravel package | ❌ NO - Python CLI/library | ❌ NO - hosted Python/TS workflow | ❌ NO - Python library | ❌ NO - Node/YAML CLI | ❌ NO - Python library |
| Runs inside your app container | ✅ YES - resolves Laravel services directly | |||||
| Local-first storage | ✅ YES - YAML datasets + JSON/Markdown reports | ❌ NO - LangSmith cloud workspace | ✅ YES - local datasets/results | ✅ YES - local YAML/results | ||
| Read-only report API | ✅ YES - opt-in Laravel routes for report listing/show, cohorts, histograms, artifact download, and row CSV export | ✅ YES - hosted experiment API | ||||
| Built-in metrics | ✅ YES - offline exact/contains/regex/ROUGE-L/citation plus fakeable cosine/BERTScore-like/judge/refusal | ✅ YES - evaluators in platform/SDK | ✅ YES - RAG-focused metrics | ✅ YES - assertions and graders | ✅ YES - built-in metrics | |
| Embedding semantic overlap | ✅ YES - cosine-embedding + bertscore-like via fakeable EmbeddingClient | ✅ YES - RAG embedding metrics | ✅ YES - semantic metrics | |||
| Deterministic no-network tests | ✅ YES - Http::fake, fake LLM/embedding clients | |||||
| LLM-as-judge | ✅ YES - schema-checked, fakeable judge client | ✅ YES - model-graded evals | ✅ YES - evaluators | ✅ YES - LLM metrics | ✅ YES - rubric/grader assertions | ✅ YES - LLM metrics |
| Refusal quality / safety judge | ✅ YES - refusal-quality with required metadata + strict JSON schema | ✅ YES - safety/red-team assertions | ✅ YES - safety metrics | |||
| Adversarial red-team seeds | ✅ YES - opt-in Laravel seed factory for 10 categories | ✅ YES - red-team plugins | ✅ YES - safety test cases | |||
| Adversarial CLI lane | ✅ YES - eval-harness:adversarial with eval:adversarial alias, saved outputs, and batch options |
✅ YES - red-team CLI workflow | ✅ YES - safety test runner | |||
| Adversarial compliance mapping | ✅ YES - JSON/Markdown category + OWASP/NIST/EU AI Act summaries | ✅ YES - red-team category reporting | ||||
| Adversarial run history manifests | ✅ YES - local JSON manifest retains adversarial summaries and clean baselines | ✅ YES - hosted experiment history | ✅ YES - monitoring/history workflows | |||
| Adversarial regression gate | ✅ YES - --regression-gate fails on macro-F1 or metric drops from local manifests |
✅ YES - hosted experiment comparisons | ✅ YES - threshold/regression workflows | ✅ YES - test assertions/regression workflows | ||
| Scheduled/continuous monitoring | ✅ YES - Laravel Scheduler/CI cron guidance with manifests, Horizon queues, gates, and failure promotion | ✅ YES - hosted monitoring workflows | ✅ YES - CLI/CI monitoring workflows | |||
| Failure promotion to datasets | ✅ YES - --promote-failures exports failed adversarial samples to YAML seeds |
✅ YES - trace-to-dataset workflows | ✅ YES - failure-driven test cases | ✅ YES - failed test cases can become datasets | ||
| Citation evidence spans | ✅ YES - citation_evidence requires marker + quote match | ✅ YES - RAG faithfulness/context metrics | ✅ YES - RAG faithfulness metrics | |||
| Cost/token/latency summaries | ✅ YES - built-in provider usage + JSON/Markdown summaries | ✅ YES - experiment usage analytics | ✅ YES - usage/cost hooks | |||
| Runtime retry / strict exception controls | ✅ YES - normalized timeouts, connection/429/5xx retries, optional raise_exceptions | ✅ YES - runtime metric settings | ||||
| Provider choice | ✅ YES - any OpenAI-compatible endpoint via Laravel HTTP | ✅ YES - multi-provider ecosystem | ✅ YES - via integrations | ✅ YES - multi-provider | ✅ YES - multi-provider | |
| CI gate | ✅ YES - Artisan command with non-zero failure exit | ✅ YES - CLI gate | ✅ YES - test runner/CI flow | |||
| Queue/Horizon batch execution | ✅ YES - SerialBatch + LazyParallelBatch for Laravel queues/Horizon | ❌ NO - not Laravel queues | ❌ NO - hosted tracing/evals | ❌ NO - not Laravel queues | ❌ NO - external CLI concurrency | ❌ NO - not Laravel queues |
| Named operational profiles | ✅ YES - --batch-profile=ci|smoke|nightly with host-app overrides under eval-harness.batches.profiles.* |
❌ NO - custom Python wrappers | ❌ NO - custom Python wrappers | |||
| Producer-side backpressure | ✅ YES - --chunk-size, --rate-limit, --rate-window-seconds with monotonic sliding-window math |
❌ NO - per-eval concurrency only | ❌ NO - in-process only | ❌ NO - in-process only | ||
| Progress checkpoints + terminal status | ✅ YES - --checkpoint-every plus optional BatchProgressReporter / BatchTerminalProgressReporter bindings |
❌ NO - log-tail only | ✅ YES - hosted run progress | |||
| Eval sets / multi-dataset runs | ✅ YES - EvalSetDefinition + resumable manifests | ✅ YES - oaievalset |
✅ YES - dataset experiments | ✅ YES - suites/configs | ✅ YES - metric collections/test suites | |
| Resume interrupted multi-dataset progress | ✅ YES - explicit per-dataset resume manifest | ❌ NO - no mid-eval resume | ||||
| Cohorts / tags / facets | ✅ YES - tag cohorts in JSON/Markdown | ✅ YES - dataset filtering/metadata | ✅ YES - metadata/config-driven views | |||
| Saved-output assertions | ✅ YES - --outputs and Eval::scoreOutputs() |
✅ YES - assertion-first workflow | ✅ YES - test-case assertions | |||
| Auditable in PR diff | ✅ YES - YAML datasets + stable JSON/Markdown artifacts | ❌ NO - cloud-first | ✅ YES - code/data files | ✅ YES - YAML config | ✅ YES - Python test files | |
| Vendor lock-in | ✅ YES - headless, local-first, provider-agnostic | ❌ NO - LangSmith workspace | ✅ YES - OSS library | ✅ YES - OSS CLI | ||
| Cost to evaluate 200 offline samples | ✅ YES - free for offline metrics and faked providers | ❌ NO - cloud/API usage |
The Python-stack tools are excellent if your stack is Python. If your
RAG pipeline lives in a Laravel monolith, eval-harness is the
shortest path from "we have AI in prod" to "we have a regression
test for our AI in prod".
composer require padosoft/eval-harnessThe package is auto-discovered. No config/app.php edits required.
Optional config publishing:
php artisan vendor:publish --tag=eval-harness-configThis drops config/eval-harness.php into your app where you can
override the embeddings + judge endpoints / models / API keys.
| eval-harness | PHP | Laravel | laravel/ai SDK | symfony/yaml |
|---|---|---|---|---|
| 0.x (current) | 8.3 / 8.4 / 8.5 | 12.x / 13.x | ^0.6 | ^7 / ^8 |
eval/golden/factuality.yml:
schema_version: eval-harness.dataset.v1
name: rag.factuality.fy2026
samples:
- id: capital-france
input:
question: "What is the capital of France?"
expected_output: "Paris"
metadata:
tags: [geography, easy]
- id: refund-policy
input:
question: "How many days do I have to return an order?"
expected_output: "30 days from delivery."
metadata:
tags: [policy, support]schema_version is optional for existing datasets. If omitted, the
loader defaults to eval-harness.dataset.v1.
app/Console/EvalRegistrar.php:
<?php
namespace App\Console;
use Illuminate\Contracts\Container\Container;
use Padosoft\EvalHarness\EvalEngine;
class EvalRegistrar
{
public function __construct(private readonly Container $container) {}
public function __invoke(EvalEngine $engine): void
{
$engine->dataset('rag.factuality.fy2026')
->loadFromYaml(base_path('eval/golden/factuality.yml'))
->withMetrics(['exact-match', 'cosine-embedding'])
->register();
$this->container->bind('eval-harness.sut', fn () =>
fn (array $input): string => app(\App\Rag\KnowledgeAgent::class)
->answer($input['question']),
);
}
}php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\Console\EvalRegistrar" \
--json --out=factuality.jsonExit code is 0 if every metric scored cleanly, non-zero otherwise.
Wire that into the same tests.yml workflow that runs your PHPUnit
suite and you've got a regression gate.
When another job already generated model responses, keep the same dataset and score those outputs directly:
{
"outputs": {
"capital-france": "Paris",
"refund-policy": "30 days from delivery."
}
}php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\Console\EvalRegistrar" \
--outputs=eval/outputs/factuality.json \
--json --out=factuality.json--outputs accepts JSON or YAML, map form (outputs.sample_id) or
list form (outputs[].id + outputs[].actual_output). Relative
--out paths use the configured reports disk and path prefix
(eval-harness/reports by default). Add --raw-path only when you
want a literal filesystem path and its parent directory already
exists. The registrar still registers the dataset; no
eval-harness.sut binding is required for this mode.
php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\Console\EvalRegistrar"# Eval report — rag.factuality.fy2026
_Run completed in 2.41s over 30 samples (0 failures captured)._
## Summary
| total samples | total failures | duration seconds |
| --- | --- | --- |
| 30 | 0 | 2.41 |
## Per-metric aggregates
| metric | mean | p50 | p95 | pass-rate (>= 0.5) |
| --- | --- | --- | --- | --- |
| exact-match | 0.7333 | 1.0000 | 1.0000 | 0.7333 |
| cosine-embedding | 0.9012 | 0.9421 | 0.9893 | 0.9667 |
## Macro-F1 (avg pass-rate across all metrics): 0.8500
## Cohorts by metadata.tags
| cohort | samples | metric | mean | p50 | p95 | pass-rate (>= 0.5) |
| --- | --- | --- | --- | --- | --- | --- |
| geography | 12 | exact-match | 0.9500 | 1.0000 | 1.0000 | 0.9500 |
| refund-policy | 8 | exact-match | 0.6000 | 0.5000 | 1.0000 | 0.6000 |
## Score histograms
### exact-match
| score range | count |
| --- | --- |
| 0.0-0.1 | 8 |
| 0.9-1.0 inclusive | 22 |
The package can register opt-in, read-only routes for a separate Laravel admin/UI package to consume stored report artifacts. Routes are disabled by default because this package does not bundle authentication; enable them only behind your host app's existing admin middleware.
// config/eval-harness.php
'api' => [
'enabled' => true,
'prefix' => 'admin/eval-harness/api',
'middleware' => ['web', 'auth'],
'trend' => [
'max_files_scanned' => 5000,
],
],With the API enabled, GET /admin/eval-harness/api/reports lists JSON and
Markdown artifacts from the configured reports disk/prefix, and
GET /admin/eval-harness/api/reports/{id} shows one artifact by URL-safe id.
Additional read-only contracts are now available for UI consumers:
GET /admin/eval-harness/api/reports/{id}/cohortsfor cohort summaries.GET /admin/eval-harness/api/reports/{id}/histogramsfor score distribution buckets.GET /admin/eval-harness/api/reports/{id}/rows.csvfor CSV sample rows.GET /admin/eval-harness/api/reports/{id}/downloadfor direct artifact download.GET /admin/eval-harness/api/reports/{id}/diff/{otherId}for signed report deltas.GET /admin/eval-harness/api/adversarial/manifestsandGET /admin/eval-harness/api/adversarial/manifests/{name}for adversarial run manifest discovery.GET /admin/eval-harness/api/batches/liveandGET /admin/eval-harness/api/batches/{id}/progressfor live lazy-parallel batch monitoring.GET /admin/eval-harness/api/datasets/{name}/trend?limit=Nfor chronological dataset trend points.- JSON examples and contract notes are documented in
docs/REPORT_API_CONTRACT.md.
use Padosoft\EvalHarness\Datasets\DatasetSample;
use Padosoft\EvalHarness\Facades\EvalFacade as Eval;
Eval::dataset('rag.smoke')
->withSamples([
new DatasetSample(id: 's1', input: ['q' => 'hi'], expectedOutput: 'hello'),
new DatasetSample(id: 's2', input: ['q' => 'bye'], expectedOutput: 'goodbye'),
])
->withMetrics(['exact-match'])
->register();
$report = Eval::scoreOutputs('rag.smoke', [
's1' => 'hello',
's2' => 'wrong answer',
]);use Padosoft\EvalHarness\Datasets\DatasetSample;
use Padosoft\EvalHarness\Metrics\Metric;
use Padosoft\EvalHarness\Metrics\MetricScore;
class JaccardWordOverlapMetric implements Metric
{
public function name(): string
{
return 'jaccard-words';
}
public function score(DatasetSample $sample, string $actualOutput): MetricScore
{
$expected = array_unique(preg_split('/\\s+/', strtolower((string) $sample->expectedOutput)));
$actual = array_unique(preg_split('/\\s+/', strtolower($actualOutput)));
$union = array_unique(array_merge($expected, $actual));
if ($union === []) {
return new MetricScore(0.0);
}
$intersection = array_intersect($expected, $actual);
return new MetricScore(count($intersection) / count($union));
}
}
// Wire it into a dataset:
Eval::dataset('rag.recall')
->loadFromYaml(base_path('eval/golden/recall.yml'))
->withMetrics([new JaccardWordOverlapMetric(), 'exact-match'])
->register();# .github/workflows/eval-gate.yml
- name: Run RAG regression gate
env:
EVAL_HARNESS_JUDGE_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\Console\EvalRegistrar" \
--json --out=eval-report.json
- uses: actions/upload-artifact@v4
if: always()
with:
name: eval-report
path: eval-report.json--batch=lazy-parallel dispatches one queue job per sample and then
assembles outputs in dataset order through the shared batch result
store. It requires the SUT to be a container-resolvable concrete
SampleRunner class that queue workers can resolve through the
Laravel container.
Constructor-injected object dependencies are supported when the worker
container can resolve an equivalent fresh runner. Arbitrary callables,
closures, anonymous runners, optional/defaulted constructor state,
scalar/array/null runner properties, and caller-specific object
configuration remain serial-only because queued jobs carry only the
runner class name.
use App\Eval\MyRagRunner;
$this->app->bind('eval-harness.sut', MyRagRunner::class);php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\\Console\\EvalQueueRegistrar" \
--batch=lazy-parallel \
--concurrency=4 \
--queue=evals \
--timeout=60 \
--batch-timeout=300Use Laravel's sync queue driver for unit tests. In production, run
Horizon workers on the chosen queue and set
EVAL_HARNESS_BATCH_CACHE_STORE to a cache backend shared by the
command process and workers so queued sample outputs can be collected
for report assembly. --concurrency is the lazy-parallel producer
fan-out cap and is also the default dispatch window size; pass
--chunk-size=N (must be <= --concurrency) for tighter backpressure.
The producer waits after each chunk completes before dispatching the
next, so when --chunk-size < --concurrency, chunk-size becomes the
effective in-flight limit per producer process, not concurrency.
Total worker pool demand scales with concurrent producers: if K eval
commands run at the same time, peak in-flight demand is roughly
chunk-size × K. Size Horizon worker pool capacity for the actual
peak (chunk-size × concurrent producers) — not just one producer's
chunk-size — or the queue will build a backlog. Worker counts
themselves are configured in Horizon.
--timeout is the per-sample job timeout; --batch-timeout caps the
producer's wait on each dispatch window. It bounds BOTH the dispatch
phase (including any producer-side --rate-limit pauses) AND the
result-collection phase: when the timeout fires before all queued
outputs land the command reports the missing samples; when dispatch
itself consumes the budget (for example because a low rate limit
throttles the producer) the command fails with an explicit
"chunk dispatch consumed the full ... wait timeout" diagnostic that
reports how many samples were still undispatched. Lower
--chunk-size, relax --rate-limit, or raise --batch-timeout to
fix it. --batch-timeout is a hard wall-clock cap only on real
queue drivers (Redis, database, beanstalk — the documented Horizon
path) where dispatch() returns immediately. On the sync queue
driver dispatch() executes the job inline, so an individual slow
sample can run arbitrarily longer than the chunk deadline before
control returns. The package only sets the queue job's $timeout
property — Laravel's queue workers honour it, but the sync driver
does NOT enforce it because there is no worker process. On sync,
neither --batch-timeout nor --timeout bounds per-sample runtime;
slow runners can take arbitrarily long. Use a real queue driver in
production for any wall-clock guarantee. Programmatic external dispatch() / collectOutputs()
flows can set BatchOptions::lazyParallel(resultTtlSeconds: ...) to
keep result metadata and sample outputs alive long enough for delayed
collection.
See docs/HORIZON_BATCH_QUEUES.md for
Horizon supervisor, cache-store, and timeout sizing guidance.
--batch-profile=ci|smoke|nightly applies a named operational preset
of batch defaults; explicit options always win, so profiles never lock
operators in. CI lanes get sane lazy-parallel defaults, smoke checks
stay serial, and nightly runs get throttled dispatch with checkpoints.
# CI gate: lazy-parallel, 4 concurrent samples, 30s job timeout, checkpoints every 25 samples.
php artisan eval-harness:run rag.factuality.fy2026 \
--batch-profile=ci \
--queue=evals \
--json --out=evals/ci-rag.json
# Nightly long run: 16 concurrent samples, throttled at 60 dispatches/60s.
php artisan eval-harness:run rag.factuality.fy2026 \
--batch-profile=nightly \
--queue=evals-nightly \
--json --out=evals/nightly-rag.jsonBackpressure flags work with any lazy-parallel profile or with
--batch=lazy-parallel:
--chunk-size=Nnarrows the producer dispatch window for tighter backpressure (defaults to--concurrency; must be<= --concurrency, since--concurrencyis the fan-out cap).--rate-limit=N --rate-window-seconds=Wthrottles producer dispatch to N samples per W-second rolling window.--checkpoint-every=Nemits structured progress events every N completed samples; bind a customBatchProgressReporterto forward them to logs or dashboards. Dashboards that need to distinguish a finished failed batch from a stalled one should implement the optionalBatchTerminalProgressReportersub-contract instead — it adds areportTerminal(...)callback with explicitsuccess/failure/emptystatus. See docs/HORIZON_BATCH_QUEUES.md for an example binding.
To clear an inherited numeric profile value for a one-off run without
redefining the profile, pass none (or null) on the corresponding
flag. For example, with --batch-profile=nightly (which sets
rate_limit=60, rate_window_seconds=60, checkpoint_every=100),
--rate-limit=none --checkpoint-every=none disables both for that
single invocation while keeping every other profile field. The same
sentinel works for --timeout, --batch-timeout, --chunk-size,
--rate-limit, --rate-window-seconds, --result-ttl-seconds, and
--checkpoint-every. --queue is excluded — queue names are
arbitrary strings, so override the profile in
eval-harness.batches.profiles.* config when an inherited queue must
be cleared.
Host apps can override or register additional profiles under
eval-harness.batches.profiles in config/eval-harness.php.
See docs/HORIZON_BATCH_QUEUES.md for
the full profile reference and Horizon tuning recipes.
Group registered datasets into an eval set when one CI or release gate needs to run several datasets in order. The returned manifest is stable JSON and can be stored by the host app between attempts; completed datasets are skipped when the manifest is passed back in.
use Eval;
use Padosoft\EvalHarness\Batches\BatchOptions;
use Padosoft\EvalHarness\EvalSets\EvalSetManifest;
$manifestPath = storage_path('eval/release.rag.manifest.json');
$previousManifest = null;
if (is_file($manifestPath)) {
$manifestPayload = json_decode((string) file_get_contents($manifestPath), true, flags: JSON_THROW_ON_ERROR);
$previousManifest = is_array($manifestPayload)
? EvalSetManifest::fromJson($manifestPayload)
: null;
}
$evalSet = Eval::evalSet('release.rag', [
'rag.factuality.fy2026',
'rag.refusals.fy2026',
]);
$result = Eval::runEvalSet(
$evalSet,
app(App\Eval\MyRagRunner::class),
BatchOptions::serial(),
$previousManifest ?? null,
);
file_put_contents(
$manifestPath,
json_encode($result->manifest->toJson(), JSON_PRETTY_PRINT | JSON_THROW_ON_ERROR),
);These are complete snippets you can paste into a Laravel app or CI job.
Use one dataset, one artifact path, and a deterministic failure signal in CI:
cat > .github/workflows/eval-gate.yml <<'EOF'
name: AI Regression Gate
on:
pull_request:
paths:
- 'app/**'
- 'config/**'
- 'eval/**'
- 'resources/**'
jobs:
eval-gate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup PHP
uses: shivammathur/setup-php@v2
with:
php-version: '8.3'
tools: composer:v2
- uses: shivammathur/setup-node@v3
with:
node-version: '20'
- name: Install dependencies
run: composer install --no-interaction --prefer-dist --no-progress
- name: Run eval gate
env:
EVAL_HARNESS_JUDGE_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
php artisan eval-harness:run rag.factuality.fy2026 \
--registrar="App\\Console\\EvalRegistrar" \
--batch=lazy-parallel \
--concurrency=4 \
--queue=default \
--timeout=60 \
--batch-timeout=180 \
--json \
--out=eval-report.json
- uses: actions/upload-artifact@v4
if: always()
with:
name: eval-report
path: eval-report.json
EOFRun adversarial tests on a schedule, keep a bounded local manifest, and fail when behavior regresses:
php artisan eval-harness:adversarial \
--registrar="App\\Console\\EvalRegistrar" \
--category=prompt-injection \
--category=pii-leak \
--metric=refusal-quality \
--batch=lazy-parallel \
--concurrency=2 \
--queue=adversarial \
--manifest=storage/app/adversarial-runs.json \
--manifest-retain=10 \
--regression-gate \
--regression-max-drop=5 \
--regression-metric=refusal-quality:pass_rate \
--json \
--out=adversarial-nightly.jsonIn Laravel Scheduler, dispatch that command via the schedule:run pipeline
and rotate artifacts with normal deployment hygiene.
Use the opt-in Laravel report API as a source of truth for charts and CSV export:
curl -sS \
-H "Accept: application/json" \
"$APP_URL/admin/eval-harness/api/reports" \
| jq '.artifacts[] | select(.id|test("factuality")) | {id, type, size}'curl -sS \
"$APP_URL/admin/eval-harness/api/reports/<url-safe-id>/rows.csv" \
-H "Accept: text/csv" \
> eval-rows.csvThe examples above use stable API schema identifiers documented in
docs/REPORT_API_CONTRACT.md.
This package stays headless, but it already has a polished companion web admin
panel at padosoft/eval-harness-admin.
Use that repository when you want a ready-made dashboard for browsing stored
reports, comparing regressions, inspecting adversarial manifests, and following
live batch progress through this package's read-only API contracts.
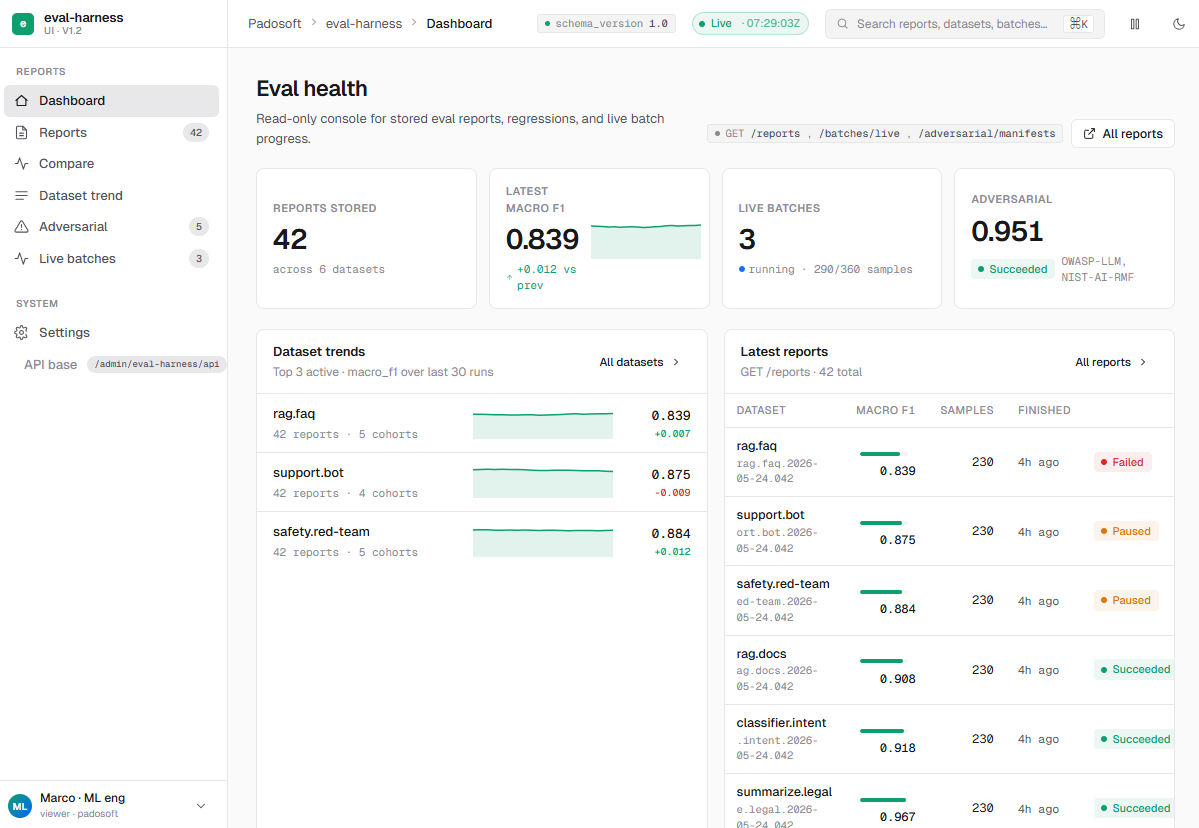
The UI package spec is documented in
docs/UI_PACKAGE_SPEC.md. It covers the intended
read-only admin screens: Dashboard, Reports list, Report detail, Compare,
Trend, Adversarial manifests, and Live batches.
v1.0 marks the package contract baseline and introduces explicit guidance on
semantic compatibility:
- Versioned, additive report and dataset schemas (
eval-harness.report.v1,eval-harness.dataset.v1). - API payload versioning (
eval-harness.api.v1). - Queue manifest compatibility by report schema / dataset / metric set signatures.
- Stable command contracts for
eval-harness:runandeval-harness:adversarialwith additive extension.
Read full details before a major upgrade:
For end users upgrading from pre-1.0, also check the changelog and keep
composer pins strict to avoid surprise majors.
config/eval-harness.php (after vendor:publish):
use Padosoft\EvalHarness\Support\RuntimeOptions;
use Padosoft\EvalHarness\Support\TimeoutNormalizer;
return [
'metrics' => [
'cosine_embedding' => [
'endpoint' => env('EVAL_HARNESS_EMBEDDINGS_ENDPOINT', 'https://api.openai.com/v1/embeddings'),
'api_key' => env('EVAL_HARNESS_EMBEDDINGS_API_KEY', env('OPENAI_API_KEY', '')),
'model' => env('EVAL_HARNESS_EMBEDDINGS_MODEL', 'text-embedding-3-small'),
'timeout_seconds' => TimeoutNormalizer::normalize(env('EVAL_HARNESS_EMBEDDINGS_TIMEOUT'), 30),
],
'llm_as_judge' => [
'endpoint' => env('EVAL_HARNESS_JUDGE_ENDPOINT', 'https://api.openai.com/v1/chat/completions'),
'api_key' => env('EVAL_HARNESS_JUDGE_API_KEY', env('OPENAI_API_KEY', '')),
'model' => env('EVAL_HARNESS_JUDGE_MODEL', 'gpt-4o-mini'),
'timeout_seconds' => TimeoutNormalizer::normalize(env('EVAL_HARNESS_JUDGE_TIMEOUT'), 60),
'prompt_template' => env('EVAL_HARNESS_JUDGE_PROMPT_TEMPLATE'),
],
],
'runtime' => [
'raise_exceptions' => RuntimeOptions::normalizeBoolean(env('EVAL_HARNESS_RAISE_EXCEPTIONS'), false),
'provider_retry_attempts' => RuntimeOptions::normalizeNonNegativeInt(env('EVAL_HARNESS_PROVIDER_RETRY_ATTEMPTS'), 0),
'provider_retry_sleep_milliseconds' => RuntimeOptions::normalizeNonNegativeInt(env('EVAL_HARNESS_PROVIDER_RETRY_SLEEP_MS'), 100),
],
'reports' => [
'disk' => env('EVAL_HARNESS_REPORTS_DISK', 'local'),
'path_prefix' => env('EVAL_HARNESS_REPORTS_PATH', 'eval-harness/reports'),
],
'batches' => [
'lazy_parallel' => [
'cache_store' => env('EVAL_HARNESS_BATCH_CACHE_STORE'),
'result_ttl_seconds' => TimeoutNormalizer::normalize(env('EVAL_HARNESS_BATCH_RESULT_TTL'), 3600),
'wait_timeout_seconds' => TimeoutNormalizer::normalize(env('EVAL_HARNESS_BATCH_WAIT_TIMEOUT'), 60),
],
],
];# OpenRouter
EVAL_HARNESS_JUDGE_ENDPOINT=https://openrouter.ai/api/v1/chat/completions
EVAL_HARNESS_JUDGE_API_KEY=or-your-key
EVAL_HARNESS_JUDGE_MODEL=anthropic/claude-3.5-sonnet
# Regolo (Italian sovereign infra)
EVAL_HARNESS_JUDGE_ENDPOINT=https://api.regolo.ai/v1/chat/completions
EVAL_HARNESS_JUDGE_API_KEY=rgl-your-key
EVAL_HARNESS_JUDGE_MODEL=mistral-largeThe embedding-backed metrics (cosine-embedding, bertscore-like)
use the same OpenAI-compatible embeddings endpoint (data[].embedding).
Most providers already implement that contract. Host apps can also bind
Padosoft\EvalHarness\Contracts\EmbeddingClient to route embeddings
through Laravel AI or deterministic fakes.
The judge-backed metrics (llm-as-judge, refusal-quality) share the
same chat-completions settings. refusal-quality requires each sample
to declare metadata.refusal_expected: true|false so safety/refusal
behavior is explicit in the dataset contract.
Adversarial safety/regression seeds are opt-in. Build and register them programmatically when a host app wants a red-team lane:
use Padosoft\EvalHarness\Adversarial\AdversarialCategory;
use Padosoft\EvalHarness\Adversarial\AdversarialDatasetFactory;
$factory = app(AdversarialDatasetFactory::class);
$dataset = $factory->build(categories: [
AdversarialCategory::PromptInjection,
'pii-leak',
'ssrf',
]);
app(\Padosoft\EvalHarness\EvalEngine::class)->registerDataset($dataset);Or run the built-in red-team lane directly from Artisan:
php artisan eval-harness:adversarial \
--registrar="App\Console\EvalRegistrar" \
--category=prompt-injection \
--category=pii-leak \
--metric=refusal-quality \
--manifest=storage/eval/adversarial-runs.json \
--manifest-retain=10 \
--regression-gate \
--regression-max-drop=5 \
--regression-metric=refusal-quality:mean \
--json --out=adversarial.jsoneval:adversarial is available as a short alias. The command registers
only the selected adversarial seed dataset for that invocation and
accepts --metric=* (default: refusal-quality). Two scoring modes
are supported: pass --outputs=<path> to score precomputed responses
(this path bypasses the batch contract entirely and goes straight to
scoreOutputs(), so --batch, --batch-profile, --rate-limit, and
the other dispatch flags are ignored when --outputs is set);
otherwise the SUT is invoked through the same batch contract as
eval-harness:run — --batch, --batch-profile, --concurrency,
--queue, --timeout, --batch-timeout, --chunk-size,
--rate-limit, --rate-window-seconds, --result-ttl-seconds, and
--checkpoint-every. Add
--manifest=<path> to update a
local JSON run-history manifest and --manifest-retain=N to keep a
bounded set of adversarial summaries: the newest N summaries plus any
additional failure-free baselines needed for compatible report schema,
dataset, metric names, and adversarial category/sample-count slices. Size
--manifest-retain for the number of distinct report schema, dataset,
metric, category, and sample-count slices you run, because each slice may
need its own clean baseline.
Add --regression-gate to compare the current run with the latest
compatible failure-free existing manifest entry (same report schema,
dataset, metric names, and adversarial category/sample-count slice)
before the current run is recorded. --regression-max-drop=5 means five
normalized percentage points. Repeat --regression-metric=metric or
--regression-metric=metric:mean|p50|p95|pass_rate for additional
metric aggregate checks. Configured regression metrics must exist in the
current run; missing current aggregates fail closed even when no baseline
exists yet. If no compatible failure-free baseline exists after that
validation, the command emits an explicit missing-baseline status. Runs
can advance the next compatible baseline whenever they are written to the
manifest and failure-free, including plain --manifest writes without
--regression-gate. Gated runs are recorded only when they are
failure-free and do not fail configured gate checks; metric failures and
gate failures are left out so they cannot seed broken baselines.
Add --promote-failures=eval/adversarial-failures.yml to export
low-scoring samples and samples with metric exceptions into a reloadable
dataset YAML seed. Use --promoted-dataset=adversarial.security.failures
to control the dataset name inside that YAML; otherwise it defaults to
<dataset>.failures. Promotion preserves the original sample input,
expected output, and metadata, adds
metadata.eval_harness.promoted_failure with the source dataset and
failed metric names, and intentionally omits actual model output and raw
provider error messages from the seed. If no samples fail, an existing
promotion file at that path is removed so fixed CI artifact paths do not
keep stale failure seeds.
The default factory covers 10 categories: prompt injection, jailbreak,
tool abuse, PII leak, SSRF, SQL/shell injection, ASCII smuggling,
competitor endorsement, excessive agency, and hallucination
overreliance. Samples include metadata.tags, metadata.adversarial,
metadata.refusal_expected, and metadata.refusal_policy so they can be
scored with refusal-quality and grouped in JSON/Markdown reports.
Reports expose a safe normalized adversarial subset only: category,
label, severity, and compliance frameworks. Raw prompts, refusal policy
text, and arbitrary sample metadata stay out of JSON sample rows.
The top-level JSON adversarial block aggregates category metrics and
framework counts for OWASP LLM, NIST AI RMF, and EU AI Act style
security reporting; Markdown reports render the same data under
Adversarial coverage. Manifest files use
eval-harness.adversarial-runs.v1, store stable metric aggregates plus
the safe adversarial summary, serialize command updates with a lock file,
and write through a temporary file before replacing the target path.
For recurring safety checks, see
docs/ADVERSARIAL_CONTINUOUS_MONITORING.md.
It shows how to run the adversarial lane from Laravel Scheduler or CI cron
with persistent manifests, Horizon-backed queues, regression gates, and
failure promotion while keeping this package daemon-free.
Provider retries are opt-in. EVAL_HARNESS_PROVIDER_RETRY_ATTEMPTS=2
means two extra attempts after the initial request, with
EVAL_HARNESS_PROVIDER_RETRY_SLEEP_MS between attempts. Retries apply
only to Laravel HTTP connection failures, HTTP 429, and 5xx responses.
Malformed successful responses still fail closed. By default, metric
failures are captured in the report; set
EVAL_HARNESS_RAISE_EXCEPTIONS=true when a strict CI lane should abort
on the first MetricException provider/metric contract error.
For stricter RAG groundedness, citation-groundedness accepts
metadata.citation_evidence:
metadata:
citation_evidence:
- citation: "[policy:refunds]"
quote: "Refunds are available within 30 days."Each evidence span scores only when the actual output contains both the citation marker and the quoted evidence text. Report details expose counts only, not raw citation or quote strings.
Metrics that expose provider usage can add a structured usage detail:
new MetricScore(1.0, [
'usage' => [
'prompt_tokens' => 120,
'completion_tokens' => 40,
'total_tokens' => 160,
'cost_usd' => 0.0024,
'latency_ms' => 850,
],
]);The renderers aggregate those values into top-level JSON and Markdown
usage summaries while leaving raw prompts/provider payloads out of the
report contract. JSON summaries include per-field reported counts so
consumers can distinguish "not reported" from a reported zero; Markdown
renders unreported usage totals as n/a. Provider usage attached to a
captured metric failure is still included in the aggregate summary so
malformed judge/embedding responses do not hide token or latency spend.
The built-in OpenAI-compatible embedding and judge clients automatically
attach safe usage details to their metric scores: token/cost fields from
the provider's usage object when present, including provider-reported
latency_ms when the backend returns it. They do not synthesize local
wall-clock latency, keeping reports diff-friendly across repeated runs.
┌──────────────────────────────────────────────────────────────────┐
│ EvalCommand / AdversarialCommand │
│ └─► php artisan eval-harness:run / eval-harness:adversarial │
│ └─► resolve registrar, dataset, callable/SampleRunner SUT │
└──────────────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────────┐
│ EvalEngine │
│ - dataset registry (in-memory, single source of truth) │
│ - run(dataset, sut) / runBatch(dataset, sut, BatchOptions) │
│ ├─► dispatch samples through SerialBatch or LazyParallelBatch│
│ ├─► invoke input callable or SampleInvocation callable/runner│
│ ├─► lazy-parallel jobs write outputs to BatchResultStore │
│ ├─► for each metric: score(sample, actual) │
│ │ - exception → SampleFailure │
│ │ - clean → MetricScore │
│ └─► assemble EvalReport │
└──────────────────────────────────────────────────────────────────┘
│ │
▼ ▼
┌────────────────────────────┐ ┌────────────────────────────┐
│ Metrics │ │ Reports │
│ - ExactMatchMetric │ │ - EvalReport │
│ - CosineEmbeddingMetric │ │ - MarkdownReportRenderer │
│ - BertScoreLikeMetric │ │ - JsonReportRenderer │
│ - LlmAsJudgeMetric │ │ - cohorts + histograms │
│ - RefusalQualityMetric │ │ - macroF1, p50, p95, mean │
└────────────────────────────┘ └────────────────────────────┘
MetricResolver accepts:
- A
Metricinstance (full control). - An FQCN string (resolved through the container).
- A built-in alias:
exact-match,contains,regex,rouge-l,citation-groundedness,cosine-embedding,bertscore-like,llm-as-judge,refusal-quality.
Every resolved class is asserted to implement Metric so a typo'd
FQCN fails with a clear error instead of producing a runtime
"method does not exist".
tests/Architecture/StandaloneAgnosticTest.php walks src/ and
fails the build if it finds a substring referring to:
- AskMyDocs internal symbols (
KnowledgeDocument,kb_nodes, etc.). - Sibling Padosoft packages (
padosoft/laravel-flow,padosoft/laravel-patent-box-tracker, etc.).
The package is consumed by AskMyDocs / patent-box-tracker / others
but never depends on them. Your composer require works exactly the
same whether you use AskMyDocs or not.
Every Padosoft package ships with a .claude/ pack that primes
Claude Code (or any compatible AI
coding agent) on the conventions used across the Padosoft repos:
- Skills — auto-loaded when context matches (e.g. opening a
Pull Request triggers
copilot-pr-review-loop, editing tests triggerstest-actually-tests-what-it-claims). - Rules — domain-specific guardrails (Laravel naming, query optimisation, exception handling, frontend testability).
- Agents — specialised sub-agents for reviewing PRs, investigating CI failures, anticipating Copilot review findings.
- Pattern adoption — the COMPANY-PACK + COMPANY-INVENTORY + PATTERN-ADOPTION docs explain how the conventions evolved across PRs so an AI agent can match the prevailing style on day one.
Install Claude Code, open the repo, and your agent immediately knows the house style. No prompt engineering required.
The package ships three PHPUnit testsuites:
# Default — offline, fast (1-2s)
vendor/bin/phpunit --testsuite Unit
# File-system invariants (standalone-agnostic)
vendor/bin/phpunit --testsuite Architecture
# Opt-in live test against a real LLM provider
EVAL_HARNESS_LIVE_API_KEY=sk-... vendor/bin/phpunit --testsuite LiveThe Unit and Architecture suites are run by CI on every PR
across the PHP 8.3 / 8.4 / 8.5 x Laravel 12 / 13 matrix. The Live
suite is never run by CI — invoke it explicitly when you want
to verify wire compatibility with a new provider or model.
Every test in tests/Live/ calls markTestSkipped(...) from
setUp() when EVAL_HARNESS_LIVE_API_KEY is empty. A contributor
running the default phpunit invocation never trips the live path
accidentally and never burns API credits.
Released 2026-05-05 (release notes). Builds on v1.0 with the v1.x enterprise operations and scalability add-on. All v1 contracts are preserved.
- Operational batch profiles —
--batch-profile=ci|smoke|nightlywith explicit-CLI-wins precedence and host-app overrides undereval-harness.batches.profiles.*. - Producer-side backpressure —
--chunk-size,--rate-limit,--rate-window-seconds, and--result-ttl-secondsflags backed byRateLimitWindow(monotonic clock, amortized O(1) sliding-window math) and the producer-side throttle inLazyParallelBatch. Passnoneon any nullable numeric flag to clear an inherited profile value for a one-off run. - Progress checkpoints —
--checkpoint-everyplus an optionalBatchProgressReportercontainer binding (defaultNullBatchProgressReporter). - Optional terminal status reporting —
BatchTerminalProgressReportersub-contract with explicitsuccess/failure/emptystatus and partial-wins tolerance on the failure path, so dashboards can distinguish a finished failed batch from a stalled one. - Operator-facing Horizon supervisor sizing guidance in
docs/HORIZON_BATCH_QUEUES.md(multi-producer caveat, chunk-size vs concurrency, rate-limit producer-side behavior).
No hard Horizon dependency added; the package still uses sync queues
and queue fakes in tests.
- Core feature set complete — cohort metrics, report histograms,
batch execution (
SerialBatch,LazyParallelBatch,--batch=serial,--batch=lazy-parallel), eval sets with resumable progress, standalone output assertions, additional built-in metrics, usage summaries, and runtime guardrails are fully implemented. - Adversarial lane complete — opt-in adversarial datasets
(including multi-input samples),
eval-harness:adversarial, compliance summaries, manifest retention,--regression-gate, and--promote-failuresare implemented and tested. - API contract complete — read-only report API routes/resources for listing/shows, cohort and histogram views, row CSV export, and report artifact download are implemented and documented.
- Stability and release complete — contract stability documents,
migration path from pre-1.0, and release guardrails (
Metric,EvalReport, JSON report shape, queue jobs, commands, and API resources) are now in place. - Roadmap status: all planned Macro Task items (0 through 8) have been completed; no roadmap placeholders remain.
See CONTRIBUTING.md. PRs follow the Padosoft 9-step canonical flow (R36): branch + local green + open PR with Copilot reviewer + wait for CI + wait for review + fix + repeat until zero must-fix comments + green CI + merge.
If you discover a security vulnerability, see SECURITY.md — please do not open a public issue.
Apache-2.0. See LICENSE.
Copyright © 2026 Padosoft — Lorenzo Padovani.